Texas A&M University-Corpus Christi CHEM4402 Biochemistry II Laboratory Laboratory 9: DNA Sequencing II
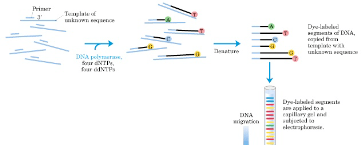
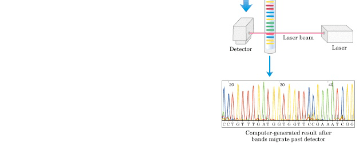
In this week’s lab, we will perform the second part of our DNA sequencing experiment. Recall from last time that a cycle sequencing reaction produces a series of fluorescently-labeled fragments that differ in length by a single nucleotide. Using capillary electrophoresis we will separate these fragments according to length. The fluorescent label provides the signal which is detected by the instrument and interpreted as referring to an “A”, “T”,”G” or “C” (figure 1). Before we can apply our sequencing reaction products to the capillary column, however, we must remove components such as unincorporated dye-labeled nucleotides, DNA polymerase, buffer salts and template DNA. These can clog the capillary and interfere with the signal. We do this by precipitating the labeled DNA fragments with glycogen, and then removing the unincorporated nucleotides and salts by washing with an ethanol solution. Our samples will then be dried down using a vacuum centrifuge. We shall re-dissolve our fragments in sample loading solution, which denatures the double-stranded DNA structure, and then freeze them prior to analysis on the DNA sequencing instrument later in the week. Results will be returned to you next week.
Figure 1. Schematic representation of a DNA cycle sequencing procedure
Materials 95% (v/v) ethanol/dH2O (cold)
Sample Loading Solution (SLS) Stop Solution
Procedure
1. Label a 1.5 ml sterile microfuge tube with your lab section (101-106) and group number (assigned by your instructor). Write down your group number in your laboratory notebook or someplace where you will remember to find it. 2. Add 4 uL Stop Solution and 1 uL 20 mg/mL glycogen (instructor)to your microfuge tube. 3. Transfer your cycle sequencing reaction to the tube and pipet gently to mix. 4. Add 60 uL of ice-cold 95% ethanol and pipet gently to mix. Place your sample in the ice bucket. Samples will be centrifuged at 14,000 rpm at 4oC for 15 minutes (Allegra 21R centrifuge). 5. Use a P-200 pipet to carefully remove the supernatant (liquid) from your DNA pellet (small, opaque, white spot near bottom of tube). 6. Add 200 uL of ice-cold 70% ethanol. DO NOT MIX. Place your sample in the ice bucket. Samples will be centrifuged at 14,000 rpm at 4oC for 5 minutes (Allegra 21R centrifuge). 7. Carefully remove ALL of the supernatant with a P-200 pipet, leaving the pellet at the bottom of the tube. 8. Repeat step 6 9. Repeat step 7 10. When all groups have completed step 9, place sample in vacuum dryer for 10-40 minutes (until dry). 11. After drying, you may no longer be able to see your pellet. Resuspend your sequencing reaction by adding 40 uL of Sample Loading Solution (SLS) to the bottom of your tube. Allow samples to sit at room temperature for 10 minutes for full resuspension. 12. Return your sample to your instructor for storage at -20oC. Samples from all laboratory sections will be placed on the genetic analyzer at the end of the week. Texas A&M University-Corpus Christi CHEM4402 Biochemistry II Laboratory Laboratory 9: DNA Sequencing II (12 pt)
(Due one week after sequencing results are returned)
Reading assignment: Lehninger Ch.8.3, section on DNA sequencing and Ch. 26.1 DNA-
Please bring a USB memory drive to collect your DNA sequence next week
1. Laboratory performance (2 pt) 2. Collect an electronic copy of your DNA sequence from your instructor. Prepare a
properly formatted figure of your sequence as follows:
a. Begin formatting your DNA sequence using the Readseq - biosequence conversion tool website (www.ebi.ac.uk/cgi-bin/readseq.cgi). Copy and paste your sequence into the Sequence data box.
b. Use the Options box (just below Sequence data) to select those features
we wish to incorporate into our sequence. If it does not already say so, select the Genbanklgb option from the Output sequence format dropdown menu. Below that, select the View in browser option. Next, select lower beneath the change sequence case to option.
c. The remaining options should be left alone. Select the Submit button at the
d. The program should return your sequence in a numbered and spaced
(every 10 nucleotides) format. Copy and paste the output (sequence only) to a Microsoft Word document (or similar).
e. Highlight the pasted sequence and set the font to Courier New with a
10 pt font size. Delete or add spaces until the sequences line up on top of one another. (1 pt)
f. Highlight the entire sequence. Set the “after” option of your paragraph
spacing (found under alignment and spacing in your formatting palette) to “6” to space out the lines of sequence.
g. Prepare a figure legend. As before it should include: figure No. (1 pt). One
sentence description of figure (1 pt). The figure legend should also include two additional items (see below)
3. Because of the nature of our cloning vector and the sequencing primer binding
site, your sequencing results will be from either the “template” or “nontemplate” DNA strands of the GFP gene. Use information from Ch. 26.1 to define these terms. (2 pt)
4. To determine which sequence (template or nontemplate) you have, look for one of
5’-ctggagttgtcccaattctt-3’(nontemplate) 5’-aagaattgggacaactccag-3’ (template)
Note that the sequence of the template strand is the reverse and complement of the nontemplate strand. You can prove this to yourself by writing the complementary sequence (T pairing with A, and G with C) just below the nontemplate sequence string. Now compare it to the template string beginning at it’s 3’end. They should be identical. Highlight (electronically) whichever nucleotide string your sequence contains. Describe the highlighted item in your figure legend and indicate whether your sequence is from the template or nontemplate strand. (2 pt)
5. Green Fluorescent Protein gets its name from its color, which is produced by a
chromophore of 3 amino acids that produce light (fluoresce) when arranged in a particular fashion. Recall that the amino acid sequence of a protein is specified by a series of 3-nucleotide codons in their genes, each codon indicating a particular amino acid. The codon sequence for the GFP chromophore is tgctatggt (nontemplate strand) or accatagca (template strand). Highlight (electronically) this sequence in your results, using a different color from the one used to indicate template or non-template strand. Be sure to describe the new highlight in your figure legend. (2 pt)
6. Use the standard genetic code (located inside back cover of your text) to identify
the amino acids specified by the codons of the chromophore sequence. Remember, if your sequencing output is from the template strand you must first determine the reverse, complementary sequence before the correct amino acid sequence can be identified. Show which amino acids are coded for by the individual codons in the chromophore. (1 pt)
Qi-Mood™ NUTRITIONALLY SUPPLIES THE IMMEDIATE METABOLIC PRECURSOR TO SEROTONIN Dietary supplementation may enhance levels of: -May reduce discomfort in patients with chronic pain -May regulate feeding patterns and have positive bariatric (weight management) effects 5-Hydroxytryptophan (5-HTP) is the immediate precursor in the biosynthesis of the neurotransmitter 5-hydroxytryptamine ( 5
FEVER MANAGEMENT IN CHILDREN DESCRIPTION- A fever means the body temperature is above normal. Your child has a fever if his: axillary (armpit) temperature is over 99.00 F The body’s average temperature when it is measured orally is 98.60 F, but it normally fluctuates during the day. Mildly increased temperature (100.4 to 101.30 F) can be caused by exercise, excessive clothing, a hot
 Texas A&M University-Corpus Christi
Texas A&M University-Corpus Christi